Математики из США и Италии проанализировали причины
успешности тех или иных мемов. В своей работе ученые не пытались
сформулировать рецепт удачного мема, что, конечно же (по мнению
интернет-пользователей), было бы очень интересно, зато нашли основной
фактор, определяющий успешность той или иной идеи.
Надо сказать, что социальные сети в академическом смысле изучались
задолго до появления первых компьютеров. В 1933 году американский
психиатр румынского происхождения Джекоб Леви Морено объявил на
медицинском конгрессе, что его новое изобретение - социограмма - впервые
позволяет взглянуть на структуру отношений людей в группе (в качестве
такой группы был выбран школьный класс). Социограмма, конечно же, с
точки зрения математики оказалась обычным графом,
которым на момент "открытия" было уже почти 200 лет, однако способ
Морено визуализировать информацию произвел фурор. Первая социограмма -
на которой, кстати, было видно, что мальчики дружат в основном с
мальчиками, а девочки - с девочками - даже попала в The New York Times.
Следующим важным этапом развития этой науки стало возникновение теории
случайных графов. В конце 50-х - начале 60-х годов эту теорию разработал
Пол Эрдеш совместно с Альфредом Реньи. Надо сказать, что уже в первых
работах по этой теории были предсказаны замечательные свойства случайных
графов, которые были подтверждены с появлением социальных сетей,
которые много позже позволили изучать взаимоотношения (пусть и
виртуальные) между людьми на глобальном уровне.
| Основные понятия теории графов | | Графом
называется пара множеств - множество вершин V и множество ребер E. У
каждого ребра есть начало и конец - это некоторые (не обязательно
различные) вершины графа. Степенью вершины называется количество
ребер, для которых эта вершина является концевой. Если концы ребра
совпадают, то при подсчете степени его концевой вершины оно учитывается
дважды. Подграфом называется пара подмножеств в V и E соответственно. Расстоянием
между двумя вершинами графа A и B называется длина кратчайшей
последовательности ребер, двигаясь по которым можно добраться из A в B. |
Так, например, математики считали, что социальные сети разбиваются на
кластеры - подграфы, внутри которых ребер много больше, чем между
разными кластерами. Кроме этого оказалось, что большинство случайных
сетей имеет конечный диаметр, то есть расстояние между любыми двумя
вершинами не превосходит некоторого числа - фактически математическая
переформулировка известной гипотезы о шести (хотя, быть может, уже и пяти) рукопожатиях. Наконец, еще одним важным свойством стало распределение степеней по вершинам. Как оказалось, оно задается распределением Пуассона.
В начале XXI века теория социальных сетей пережила настоящую революцию.
Благодаря всеобщему распространению интернета вопросы, которыми раньше
задавались только психологи и социологи лишь из научного интереса,
оказались важны для прикладников - от рекламщиков до программистов
систем распределенных вычислений. В эту науку потянулись физики,
математики и компьютерщики, которые привнесли с собой множество новых
идей и инструментов. В настоящее время статьи по моделированию сетей
можно найти в самых разных журналах - от Physical Review Letters до Аmerican journal of sociology.
Работа, о которой идет речь, появилась в Scientific Reports
- довольно авторитетном журнале, издаваемом Nature Publishing Group, к
которой относится один из самых известных в мире научных журналов Nature.
Объектом исследования математиков из США и Италии стали не сами
социальные сети, а процесс распространения информации в них. В качестве
объекта исследования выступал мем. Тут, кстати, надо сделать небольшое
отступление - дело в том, что слово мем появилось задолго до понятия интернет-мема
(хотя это одно и то же). Этот термин означает единицу передачи
культурной информации, распространяемой посредством имитации, научения,
копирования и прочих методов. Термин происходит от греческого "подобие",
и впервые появился в книге "Эгоистичный ген" этолога, эволюциониста и
популяризатора науки Ричарда Докинза в 1975 году.
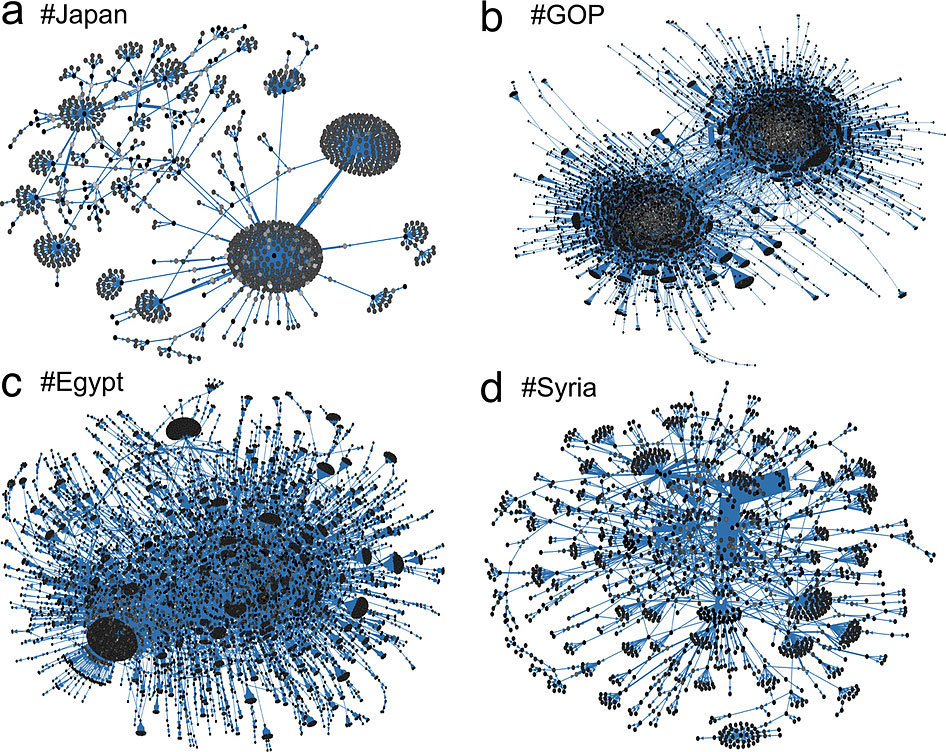
 | Структура
распространения некоторых мемов в Twitter, определяемых по хэштегам
#Japan, #Syria, #Egypt, #GOP. Изображение с сайта nature.com
(Нажмите, чтобы увеличить) |
Как бы то ни было, но исследователей интересовали самые базовые модели
распространения мемов. Дело в том, что работа по моделированию подобного
рода процессов - это, по сути, работа на ощупь. С одной стороны,
исследователи действуют так же, как и астрономы - формулируют некоторые
гипотезы, на основе которых потом сравнивают полученные на компьютере
результаты с данными, полученными на практике. Если данные согласуются,
то гипотеза считается более или менее верной. Главная трудность
моделирования процессов в социальных сетях заключается в том, что
совершенно непонятно, какие именно факторы надо учитывать, а какие -
нет. Никто не застрахован от того, что посвятит статью фактору, который,
возможно, вообще не имеет значения - как если бы астрофизики,
моделирующие эволюцию звезд, написали бы работу о том, как зависит
результат моделирования от цветов пикселей на экране во время работы.
Так, например, при изучении мемов рассматривается огромное количество
разных внешних параметров - активность пользователей, их аудитория,
качество информации, актуальность темы, определяемая внешними событиями,
однородность кластеров внутри сети (группы образуют люди со схожими
интересами) и другие. В своей работе математики не стремились построить
самую реалистичную модель - они хотели получить минимальную модель, то
есть система с минимумом предположений с одной стороны, которая бы вела
себя похожим на реальность образом.
Надо сказать, что ученые со своей задачей справились. Им удалось
построить систему, динамика которой, помимо, конечно, самой структуры
сети, управлялась одним единственным предположением - пользователи
социальной сети за раз могут следить лишь за конечным количеством тем
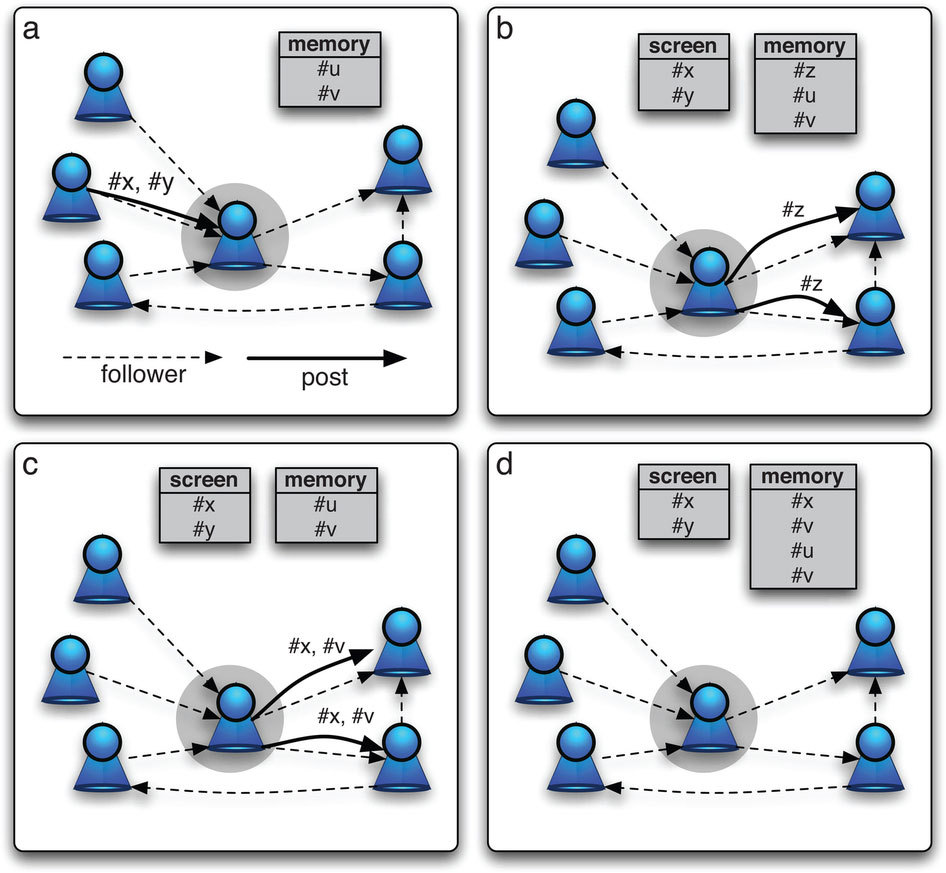
одновременно. В рамках модели каждый пользователь был агентом,
снабженным конечным списком свежих сообщений (по аналогии с Home в Twitter,
только ограниченной и фиксированной длины). Каждое сообщение может
относится только к одному мему, но в списке может встречаться сразу
несколько сообщений, посвященных одной и той же единице передачи
культурной информации. Новые сообщения добавляются сверху списка,
вытесняя те, что снизу. Помимо списка свежих сообщений пользователь
наделен памятью о мемах, которым он посвящал сообщения. Она представлена
конечным списком, устроенным так же, как и список свежих сообщений -
память конечна, и новые мемы вытесняют в ней старые.
 | Иллюстрация работы агентов в модели. Изображение с сайта nature.com
(Нажмите, чтобы увеличить) |
Для моделирования поведения пользователя используется простая
вероятностная модель - пользователь с некоторой вероятностью p может
запостить сообщение, посвященное совершенно новому мему, с вероятностью 1
- p просматривает список сообщений. Там он выбирает некоторый мем,
которому посвящает пост, либо вспоминает случайный мем из памяти и
посвящает пост ему. В работе была построена сеть с порядка 100 тысячами
пользователей и тремя миллионами взаимосвязей между ними. Полученные
данные сравнивались с данными о поведении 12,5 миллионов пользователей
Twitter в период с октября 2010 года по январь 2011 года.
По словам ученых, им удалось получить результаты, прекрасно
согласующиеся с данными микроблога. Более того, проведенный отдельно
статистический анализ показал, что гипотеза об ограниченном внимании, по
крайней мере в Twitter, действительно выполняется. Рассчитав энтропию
Шеннона, определяющую информационное разнообразие системы, для каждого
пользователя и для всей системы, они получили, что первый параметр за
изучаемый период не менялся, в то время как второй заметно рос.
Сами исследователи признают, что их результаты не дают четкого ответа на
вопрос, как запустить успешный мем. Вместе с тем, они полагают, что их
работа заложит фундамент для более сложных и реалистичных моделей в
будущем. А вот они уже, быть может, какой-то ответ на этот вопрос и
смогут дать.
Андрей Коняев
Предыдущие материалы по теме
|