описание структуры у нас в проекте выглядит следующим образом:
struct thread {
unsigned int critical_count;
unsigned int siglock;
spinlock_t lock;
unsigned int active;
unsigned int ready;
unsigned int waiting;
unsigned int state;
struct context context;
void *(*run)(void *);
void *run_arg;
union {
void *run_ret;
void *joining;
} ;
thread_stack_t stack;
__thread_id_t id;
struct task *task;
struct dlist_head thread_link;
struct sigstate sigstate;
struct sched_attr sched_attr;
thread_local_t local;
thread_cancel_t cleanups;
};
В структуре есть поля не описанные в статье (sigstate, local, cleanups) они нужны для поддержки полноценных POSIX потоков (pthread) и в рамках данной статьи не принципиальны.
Планировщик и стратегия планирования
Напомним, что теперь у нас есть структура потока, включающая в том числе контекст, этот контекст мы умеем переключать. Кроме того, у нас есть системный таймер, который отмеряет кванты времени. Иными словами, у нас готово окружение для работы планировщика.
Задача планировщика — распределять время процессора между потоками. У планировщика есть очередь готовых потоков, которой он оперирует для определения следующего активного потока. Правила, по которым планировщик выбирает очередной поток для исполнения, будем называть стратегией планирования. Основная функция стратегии планирования — работа с очередью готовых потоков: добавление, удаление и извлечение следующего готового потока. От того, как будут реализованы эти функции, будет зависеть поведение планировщика. Поскольку мы смогли определить отдельное понятие — стратегию планирования, вынесем его в отдельную сущность. Интерфейс мы описали следующим образом:
extern void runq_init(runq_t *queue);
extern void runq_insert(runq_t *queue, struct thread *thread);
extern void runq_remove(runq_t *queue, struct thread *thread);
extern struct thread *runq_extract(runq_t *queue);
extern void runq_item_init(runq_item_t *runq_link);
Рассмотрим реализацию стратегии планирования поподробнее.
Пример стратегии планирования
В качестве примера я разберу самую примитивную стратегию планирования, чтобы сосредоточиться не на тонкостях стратегии, а на особенностях вытесняющего планировщика. Потоки в этой стратегии буду обрабатываться в порядке очереди без учета приоритета: новый поток и только что отработавший свой квант помещаются в конец; поток, который получит ресурсы процессора, будет доставаться из начала.
Очередь будет представлять из себя обычный двусвязный список. Когда мы добавляем элемент, мы вставляем его в конец, а когда достаем — берем и удаляем из начала.
void runq_item_init(runq_item_t *runq_link) {
dlist_head_init(runq_link);
}
void runq_init(runq_t *queue) {
dlist_init(queue);
}
void runq_insert(runq_t *queue, struct thread *thread) {
dlist_add_prev(&thread->sched_attr.runq_link, queue);
}
void runq_remove(runq_t *queue, struct thread *thread) {
dlist_del(&thread->sched_attr.runq_link);
}
struct thread *runq_extract(runq_t *queue) {
struct thread *thread;
thread = dlist_entry(queue->next, struct thread, sched_attr.runq_link);
runq_remove(queue, thread);
return thread;
}
Планировщик
Теперь мы перейдем к самому интересному — описанию планировщика.
Запуск планировщика
Первый этап работы планировщика — его инициализация. Здесь нам необходимо обеспечить корректное окружение планировщику. Нужно подготовить очередь готовых потоков, добавить в эту очередь поток idle и запустить таймер, по которому будут отсчитываться кванты времени для исполнения потоков.
Код запуска планировщика:
int sched_init(struct thread *idle, struct thread *current) {
runq_init(&rq.queue);
rq.lock = SPIN_UNLOCKED;
sched_wakeup(idle);
sched_ticker_init();
return 0;
}
Пробуждение и запуск потока
Как мы помним из описания машины состояний, пробуждение и запуск потока для планировщика — это один и тот же процесс. Вызов этой функции есть в запуске планировщика, там мы запускаем поток idle. Что, по сути дела, происходит при пробуждении? Во-первых, снимается пометка о том, что мы ждем, то есть поток больше не находится в состоянии waiting. Затем возможны два варианта: успели мы уже уснуть или еще нет. Почему это происходит, я опишу в следующем разделе “Ожидание”. Если не успели, то поток еще находится в состоянии ready, и в таком случае пробуждение завершено. Иначе мы кладем поток в очередь планировщика, снимаем пометку о состоянии waiting, ставим ready. Кроме того, вызывается перепланирование, если приоритет пробужденного потока больше текущего. Обратите внимание на различные блокировки: все действо происходит при отключенных прерываниях. Для того, чтобы посмотреть, как пробуждение и запуск потока происходит в случае SMP, советую вам обратиться к коду проекта.
static int __sched_wakeup_ready(struct thread *t) {
int ready;
spin_protected_if (&rq.lock, (ready = t->ready))
t->waiting = false;
return ready;
}
static void __sched_wakeup_waiting(struct thread *t) {
assert(t && t->waiting);
spin_lock(&rq.lock);
__sched_enqueue_set_ready(t);
__sched_wokenup_clear_waiting(t);
spin_unlock(&rq.lock);
}
static inline void __sched_wakeup_smp_inactive(struct thread *t) {
__sched_wakeup_waiting(t);
}
int __sched_wakeup(struct thread *t) {
int was_waiting = (t->waiting && t->waiting != TW_SMP_WAKING);
if (was_waiting)
if (!__sched_wakeup_ready(t))
__sched_wakeup_smp_inactive(t);
return was_waiting;
}
int sched_wakeup(struct thread *t) {
assert(t);
return SPIN_IPL_PROTECTED_DO(&t->lock, __sched_wakeup(t));
}
Ожидание
Переход в режим ожидания и правильный выход из него (когда ожидаемое событие, наконец, случится), вероятно, самая сложная и тонкая вещь в вытесняющем планировании. Давайте рассмотрим ситуацию поподробнее.
Прежде всего, мы должны объяснить планировщику, что мы хотим дождаться какого-либо события, причем событие происходит естественно асинхронного, а нам нужно его получить синхронно. Следовательно, мы должны указать, как же планировщик определит, что событие произошло. При этом мы не знаем, когда оно может произойти, например, мы успели сказать планировщику, что ждем события, проверили, что условия его возникновения еще не выполнены, и в этот момент происходит аппаратное прерывание, которое и вырабатывает наше событие. Но поскольку мы уже выполнили проверку, то эта информация потеряется. У нас в проекте мы решили данную проблему следующим образом.
Код макроса ожидания
#define SCHED_WAIT_TIMEOUT(cond_expr, timeout) \
((cond_expr) ? 0 : ({ \
int __wait_ret = 0; \
clock_t __wait_timeout = timeout == SCHED_TIMEOUT_INFINITE ? \
SCHED_TIMEOUT_INFINITE : ms2jiffies(timeout); \
\
threadsig_lock(); \
do { \
sched_wait_prepare(); \
\
if (cond_expr) \
break; \
\
__wait_ret = sched_wait_timeout(__wait_timeout, \
&__wait_timeout); \
} while (!__wait_ret); \
\
sched_wait_cleanup(); \
\
threadsig_unlock(); \
__wait_ret; \
}))
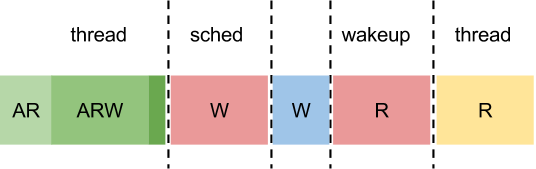
Поток у нас может находиться сразу в суперпозиции состояний. То есть когда поток засыпает, он все еще является активным и всего лишь выставляет дополнительный флаг waiting. Во время пробуждения опять же просто снимается этот флаг, и только если поток уже успел дойти до планировщика и покинуть очередь готовых потоков, он добавляется туда снова. Если рассмотреть описанную ранее ситуацию на картинке, то получится следующая картина.

A — active
R — ready
W — wait
На картинке буквами обозначено наличие состояний. Светло-зеленый цвет — состояние потока до wait_prepare, зеленый — после wait_prepare, а темно-зеленый — вызов потоком перепланирования.
Если событие не успеет произойти до перепланирования, то все просто — поток уснет и будет ждать пробуждения:
Перепланирование
Основная задача планировщика — планирование, прошу прощения за тавтологию. И мы наконец подошли к моменту когда можно разобрать как этот процесс реализован у нас в проекте.
Во-первых перепланирование должно выполняться при заблокированном планировщике. Во-вторых мы хотим дать возможность разрешить вытеснение потока или нет. Поэтому мы вынесли логику работы в отдельную функцию окружили ее вызов блокировками и вызвали ее указав, что в этом месте мы не позволяем вытеснение.
Далее идут действия с очередью готовых потоков. Если активный на момент перепланирования потока не собирается уснуть, то есть если у него не выставлено состояние waiting, мы просто добавим его в очередь потоков планировщика. Затем мы достаем самый приоритетный поток из очереди. Правила нахождения этого потока реализуются с помощью стратегии планирования.
Затем если текущий активный поток совпадает с тем который мы достали из очереди, нам не нужно перепланирование и мы можем просто выйти и продолжить выполнение потока. В случае же если требуется перепланирование, вызывается функция sched_switch, в которой выполняются действия необходимые планировщику и главное вызывается context_switch который мы рассматривали выше.
Если же поток собирается уснуть, находится в состоянии waiting, то он не попадает в очередь планировщика, и с него снимают метку ready.
В конце происходит обработка сигналов, но как я отмечала выше, это выходит за рамки данной статьи.
static void sched_switch(struct thread *prev, struct thread *next) {
sched_prepare_switch(prev, next);
trace_point(__func__);
cpudata_var(saved_prev) = prev;
thread_set_current(next);
context_switch(&prev->context, &next->context);
prev = cpudata_var(saved_prev);
sched_finish_switch(prev);
}
static void __schedule(int preempt) {
struct thread *prev, *next;
ipl_t ipl;
prev = thread_self();
assert(!sched_in_interrupt());
ipl = spin_lock_ipl(&rq.lock);
if (!preempt && prev->waiting)
prev->ready = false;
else
__sched_enqueue(prev);
next = runq_extract(&rq.queue);
spin_unlock(&rq.lock);
if (prev != next)
sched_switch(prev, next);
ipl_restore(ipl);
assert(thread_self() == prev);
if (!prev->siglock) {
thread_signal_handle();
}
}
void schedule(void) {
sched_lock();
__schedule(0);
sched_unlock();
}
Проверка работы многопоточности
В качестве примера я использовала следующий код:
#include <stdint.h>
#include <errno.h>
#include <stdio.h>
#include <util/array.h>
#include <kernel/thread.h>
#include <framework/example/self.h>
EMBOX_EXAMPLE(run);
#define CONF_THREADS_QUANTITY 0x8 /* number of executing threads */
#define CONF_HANDLER_REPEAT_NUMBER 300 /* number of circle loop repeats*/
static void *thread_handler(void *args) {
int i;
for(i = 0; i < CONF_HANDLER_REPEAT_NUMBER; i ++) {
printf("%d", *(int *)args);
}
return thread_self();
}
static int run(int argc, char **argv) {
struct thread *thr[CONF_THREADS_QUANTITY];
int data[CONF_THREADS_QUANTITY];
void *ret;
int i;
for(i = 0; i < ARRAY_SIZE(thr); i ++) {
data[i] = i;
thr[i] = thread_create(0, thread_handler, &data[i]);
}
for(i = 0; i < ARRAY_SIZE(thr); i ++) {
thread_join(thr[i], &ret);
}
printf("\n");
return ENOERR;
}
Собственно, это почти обычное приложение. Макрос EMBOX_EXAMPLE(run) задает точку входа в специфичный тип наших модулей. Функция thread_join дожидается завершения потока, пока я ее тоже не рассматривала. И так уже очень много получилось для одной статьи.
Результат запуска этого примера на qemu в составе нашего проекта следующий

Как видно из результатов, сначала созданные потоки выполняются один за другим, планировщик дает им время по очереди. В конце некоторое расхождение. Я думаю, это следствие того, что у планировщика достаточно грубая точность (не сопоставимая с выводом одного символа на экран). Поэтому на первых проходах потоки успевают выполнить разное количество циклов.
В общем, кто хочет поиграться, можно
скачать проект и попробовать все вышеописанное на практике.
Если тема интересна, я попробую продолжить рассказ о планировании, еще достаточно много тем осталось не раскрытыми.
